FAIR Data Management#
The ‘FAIR Guiding Principles for scientific data management and stewardship’ is build upon the use of machine-actionability metadata to find, access, interoperate, combine, and directly reuse data with minimal human intervention.
To improve the quality of the reported data and to maximise the potential for reuse the set of metadata must be sufficient to allow for unambiguous interpretation of the associated data. For metadata management Minimum Information standards are used in the Life Sciences consisting of two parts. Firstly, for each assay and associated data type there is a community accepted checklist of reporting requirements. Secondly, an obligatory data format is used for reporting essential metadata to ensure machine-actionability.
FAIR BY DESIGN#
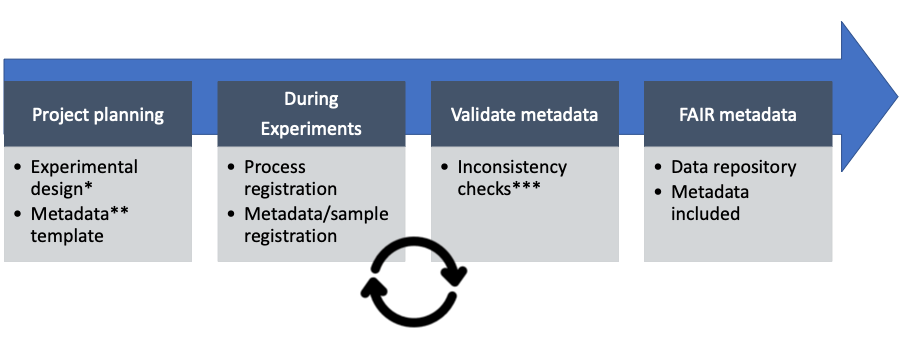
In UNLOCK, we work according to the fairbydesign principles. This is to ensure that projects are Findable, Accessible, Interoperable and Reusable from the start. Throughout all the stages of the project FAIR principles are applied to improve your quality research.
This process is initiated by project planning and experimental design using the FAIR Data Station https://fairds.fairbydesign.nl. In here you can record all metadata important for your research. The information is then transformed into a Linked Data file which can be used for automatic processing of data sets, publishing and exploratory queries over a multitude of studies.
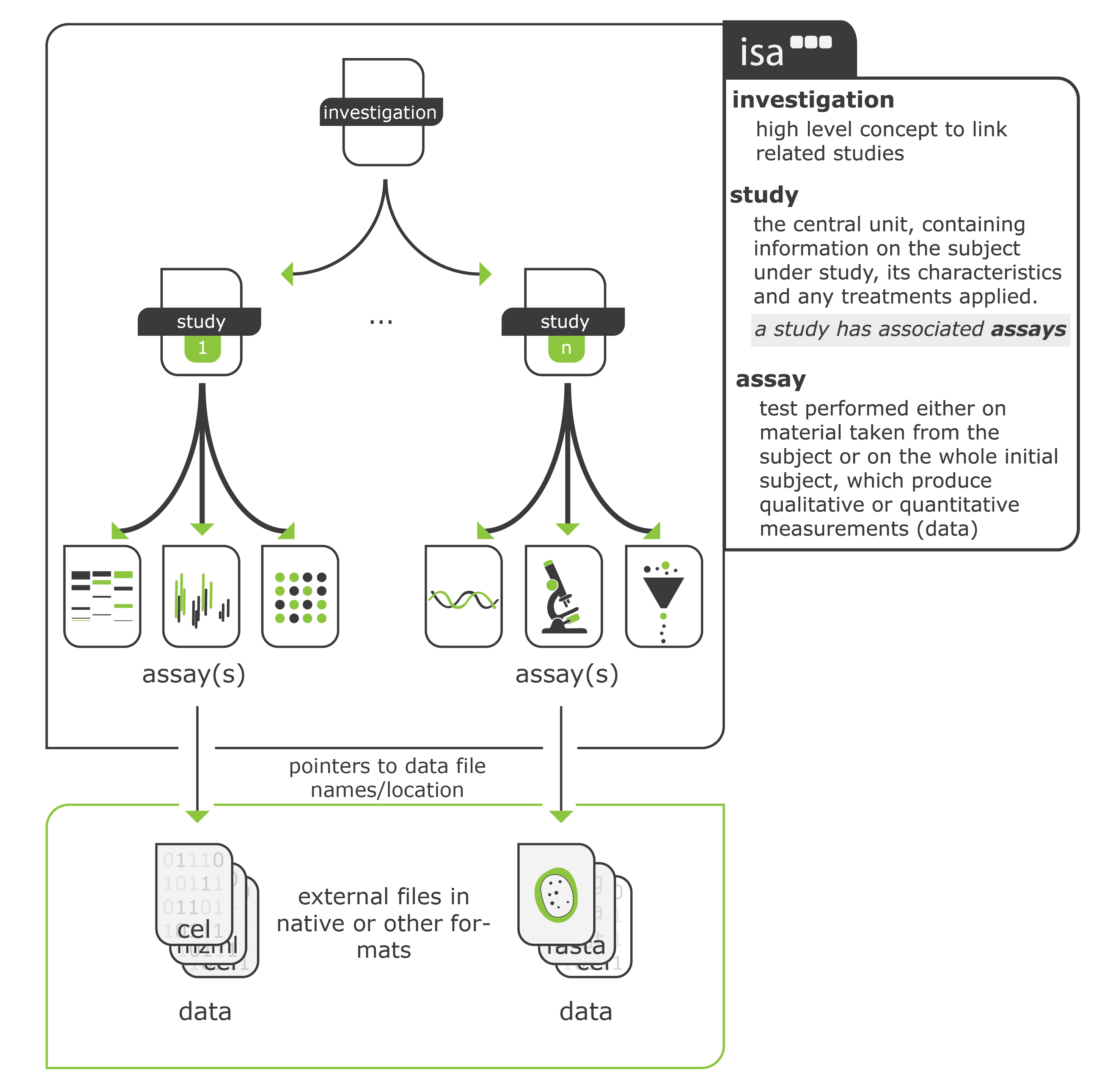
Role of ISA#
The core of our Linked metadata system is based on the ISA format (http://isa-tools.org). ISA which stands for Investigation, Study and Assay is a metadata framework used to manage a diverse set of experiments from the life, environmental and biomedical sciences. The Investigation (the project context), Study (a unit of research) and Assay (analytical measurements) concepts are incorporated into the UNLOCK infrastructure and expanded with other standards such as JERM, MIAPPE and MIxS.
Ontologies#
A set of ontologies are combined and used to support the metadata model. This model is based on the ISA structrure in which the URI’s from ISA have been mapped to the Just Enough Results Model (http://jermontology.org). Through JERM the Project class was added to improve the alignment with the FAIRDOM Hub (http://fairdomhub.org) and to improve the categorisation of multiple investigations under one funding agency (the project).
In biological studies samples play a key role and in almost all research projects more then one subject, entity or environment are being analysed. The addition of Observation Unit from the MIAPPE ontology solves the problem of the missing association between sample and study.

API#
The ontology is written in a combination of OWL and ShEx enabling http://empusa.org to generate a JAVA api for integration purposes. The API available at http://download.systemsbiology.nl/#/unlock/ is used to create, manage and query the RDF datasets generated throughout various applications. First and foremost the ontology is used by default in the FAIR Data Station, accessible at https://fairds.fairbydesign.nl to validate and generate structured RDF data from metadata excel sheets.
The generated RDF datasets are then used to drive the computational work using the metadata information available in the RDF datasets and the Common Workflow Language for processing raw data to information.
Setup your own FAIR Data Staion#
To quickly get started download the application from http://download.systemsbiology.nl/#/unlock/ and download the fairds-version.jar file.
To start the program in a terminal (Linux/Mac) or Command Prompt in Windows by typing: java -jar fairds-VERSION.jar
When you see the following line, the application has started…
Tomcat started on port(s): 8083 (http) with context path ''
Now you can access the application using your browser at http://localhost:8083 Here you can generate your templates and validate your metadata!
There is also a docker image available for the FAIR Data Station. To quick start a simple container without modification possibilities use the following command:
docker run -p 8083:8083 registry.gitlab.com/m-unlock/fairds:latest
This will start the FAIR Data station and you can access it at localhost:8083.
If you want to have access to the data files:
docker run -v $PWD/fairds_storage:/fairds_storage -p 8083:8083 registry.gitlab.com/m-unlock/fairds:latest
This will start the container and will create a folder in the location you are currently in. The metadata template will show up here in a folder created called “fairds_storage” in your current location.